



PlayAI is partnering with Groq to deliver Dialog, our market-leading voice AI model, using fast AI inference from GroqCloud™. Click...
March 6, 2025
PlayAI and LiveKit partner to bring high-performance ultra-expressive voice AI to customers

March 6, 2025
We’re announcing a partnership between LiveKit and PlayAI to give developers the tools to build high-performance voice AI capabilities, using PlayAI’s ultra-emotive Dialog model. With this partnership, developers will be able to use LiveKit Agents to route voice generations with high reliability and low-latency to users around the globe at scale.
You can start experimenting with these new capabilities by reading the guide below to start building your first real-time voice AI application. LiveKit Agents supports all of PlayAI Dialog’s functionality, including voice cloning, and AI voice generation for single and multi-speaker applications such as podcasts, narrations, and real-time applications such as voice agents.
How LiveKit Agents work
For real-time voice applications, such as voice agents, and live customer support, low latency user responses are critical to giving users an authentic, human-like experience. Typically, latencies of around 300ms TTFA (Time to First Audio) are required, meaning the network time for the request, the inference time to generate audio, and the network time to reply with audio needs to fit in that window.
The video below shows how LiveKit achieves that with PlayAI’s models.

How it works:
- An application written by a developer generates text for rendering audio
- Using LiveKit Agents, the request for audio is routed through LiveKit’s cloud to [the closest] PlayAI server cluster
- PlayAI’s inference servers generate voice audio as a stream
- The audio stream is returned through LiveKit’s cloud
However, Websockets doesn’t provide programmatic control over packet loss, which can happen frequently between client and server devices over lossy connections like WiFi or cellular data. Protocols like WebRTC are a better fit, as this was specifically designed for transferring audio with low-latency, and can adapt bitrates based on network performance. However, these can be complex to implement, so as part of this partnership, LiveKit Agents now has a PlayAI plugin that takes advantage of the underlying open-source infrastructure across a global network, simplifies WebRTC, and routes audio with the lowest latency available.
Using LiveKit with PlayAI
LiveKit has launched a new API in the Agents framework, along with hooks and components that make it easy to build low-latency, high performance voice AI apps using PlayAI’s Dialog model.
Backend code
Here’s a simple example using a LiveKit Agent in Python:
async def entrypoint(ctx: JobContext):
initial_ctx = llm.ChatContext().append(
role="system",
text=("You are a PlayAI voice assistant."),
)
await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY)
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=openai.STT(),
llm=openai.LLM(),
tts=playai.TTS(),
chat_ctx=initial_ctx,
)
agent.start(ctx.room)
if __name__ == "__main__":
cli.run_app(WorkerOptions(entrypoint_fnc=entrypoint))
Load balancing is built directly into LiveKit’s media server, so you can run this agent the exact same way on localhost, a self-hosted deployment, or on LiveKit Cloud.
Frontend
On the frontend, we have new hooks, mobile components, and visualizers that simplify wiring up your client application to your agent. Here’s an example in NextJS:
import { LiveKitRoom, RoomAudioRenderer, BarVisualizer, useVoiceAssistant } from '@livekit/components-react'
function PipelineAgent() {
const { audioTrack, state } = useVoiceAssistant()
return (
<div>
<BarVisualizer trackRef={audioTrack} state={state} />
</div>
)
}
export default function IndexPage({ token }) {
return (
<LiveKitRoom serverUrl={process.env.NEXT_PUBLIC_LIVEKIT_URL} connect={true} audio={true} token={token}>
<PipelineAgent />
<RoomAudioRenderer />
</LiveKitRoom>
)
}For examples of code similar to the above running in production, check out LiveKit’s homepage or the open-source Realtime API playground. We also have a more detailed end-to-end guide on building your own agent using the Multimodal Agent API.
Use cases
PlayAI Dialog is a low-latency voice model out-of-the-box, and with the addition of the LiveKit Agents, developers now have additional control over factors like network latency no matter where in the world the end client sits. Improving the end-to-end latency means that customers can reliably deploy real-time use cases globally, including:
- Customer support. Voice is the default channel for most customer support interactions. While pure AI solutions are not capable – yet – of handling all support enquiries, the proportion is increasing rapidly, and having an emotive, human-like voice is essential to successful call deflection.
- Voice agents. Voice agents that can handle everything from Q&A, scheduling, payments and more are exploding in popularity, including within mid-sized enterprises and SMBs as AI capabilities have risen and costs have fallen. PlayAI’s Dialog model also supports voice cloning, making it easy to create powerful, easy-to-use voice agents that act and reflect a customer’s brand.
- Gaming and entertainment. Single and multiplayer games frequently include voice interaction with other players and NPCs. PlayAI’s Dialog model can replicate almost any gaming character’s voice, tone, and emotion on demand, and at low latency
- AI characters. Multiple companies have emerged offering chat interaction with AI characters, and their usage has exploded. Offering reliable, low-latency responses with custom voices is essential to the user experience and the business model
- Consultative applications (Telehealth, mental health, executive coaching and more). PlayDialog’s emotive voices are ideal for applications where customers want to know that they’re being heard, and feel that the experience is the same, or as close as possible, to speaking with an actual human
We’d love to learn what you’re building and help however we can. Come say ‘hi’ in our Slack community or DM/mention @livekit or @play_ht on X. We can’t wait to see what you build!
Share this news
Previous Announcements

April 4, 2025
PlayAI and Groq Join Forces to Transform Voice AI
March 4, 2025
Introducing the All-New Play.ai Studio: Four Powerful New Features in One Unified Platform
We’re thrilled to announce a major upgrade to the Play.ai Studio, bringing together our most requested features and capabilities into...

February 3, 2025
PlayAI Dialog generally available; beats industry leading model 3 to 1 in human preference testing
February 3, 2025. PlayAI’s Dialog Text-to-Speech model is now in general availability, bringing multilingual capabilities, and exceptional performance to applications...
October 14, 2024
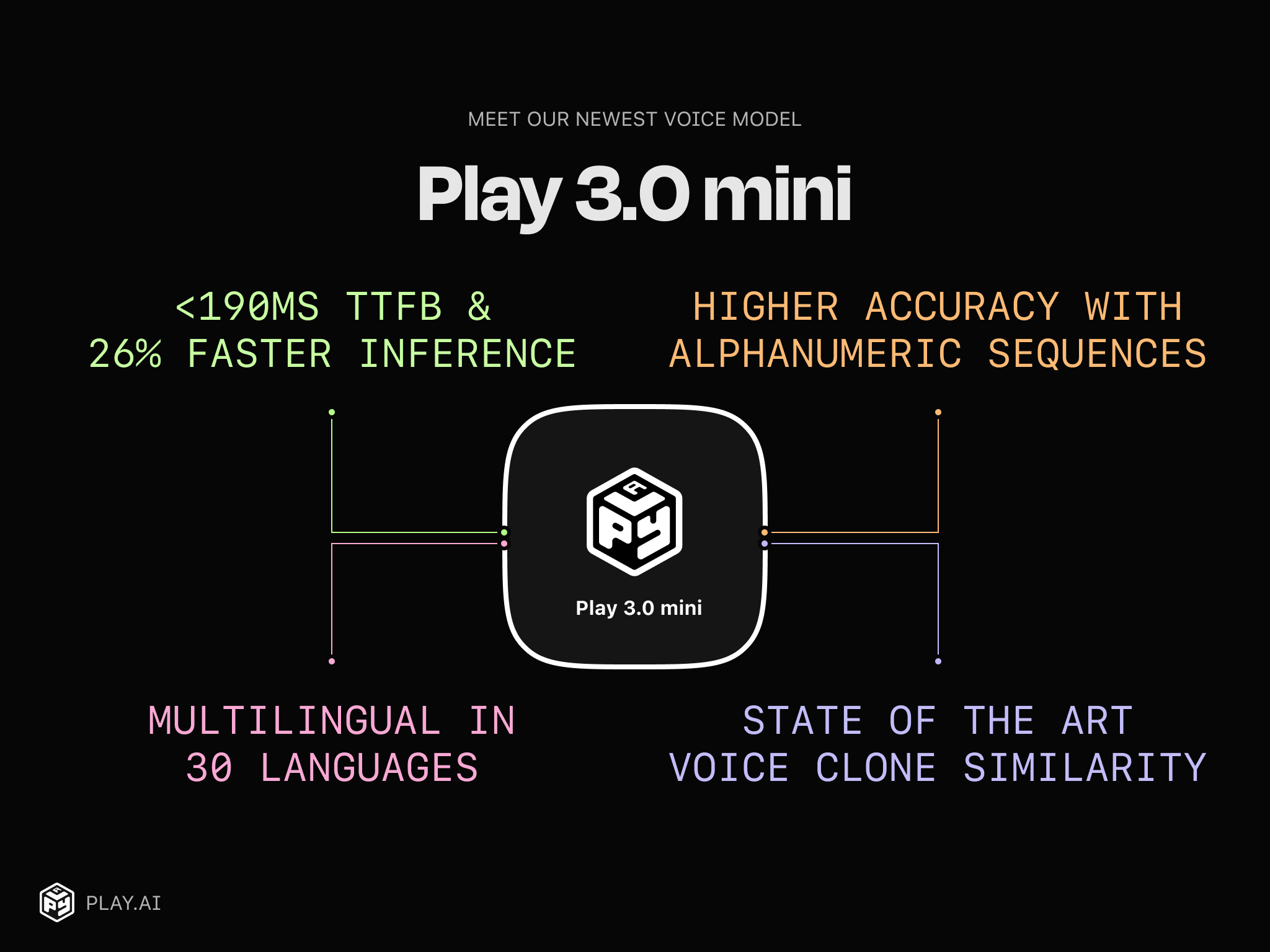
Introducing Play 3.0 mini – A lightweight, reliable and cost-efficient Multilingual Text-to-Speech model
Today we’re releasing our most capable and conversational voice model that can speak in 30+ languages using any voice or...

October 12, 2023
Introducing PlayHT 2.0 Turbo  – The Fastest Generative AI Text-to-Speech API
– The Fastest Generative AI Text-to-Speech API
TL;DR We are thrilled to announce the release of the FASTEST Voice LLM to date! Experience real-time speech streaming from...

August 9, 2023
Introducing PlayHT1.0: A Truly Realistic Text to Speech Model with Emotion and Laughter
Today we’re introducing the first ever Generative Text to Voice AI model that’s capable of synthesizing humanlike speech with incredible...

August 7, 2023
Introducing Cross-Language Voice Cloning while preserving Speaker Accent
Today we’re announcing a new feature that enables non-English speakers to clone their voices to create English speaking clones of...

August 6, 2023
Introducing PlayHT2.0: The state-of-the-art Generative Voice AI Model for Conversational Speech
Today we’re introducing a new Generative Text-to-Voice AI Model that’s trained and built to generate conversational speech. This model also...

March 29, 2023
Play.ht hits GDC 2023: After Action Report
PlayHT at GDC 2023. A full recap. We believe that AI voices have a bright future in game development. With...